معالجة اللغات الطبيعية : تحديات اللغة العربية
كتابة : زيد اليافعي
اللغة العربية و بقية اللغات
هناك العديد من اللهجات و اللغات حول أنحاء العالم. يقدر أنه هناك أكثر من 7000 لغة ولهجة حول العالم (مصدر). بالإضافة إلى ذلك معظم اللغات تختلف من ناحية القواعد وطريقة الكتابة من اليمين إلى اليسار مثل العربية أو من اليسار إلى اليمين مثل الإنجليزية. طريقة النطق تختلف كذلك بسبب وجود أحرف لا يمكن نطقها في لغات أخرى مثل الضاد في اللغة العربية. كذلك تختلف اللغات من ناحية الكتابة ، مثلاً في الكتابة اليابانية (kanji) هناك بعض الرموز التي ترمز إلى أسماء أو أفعال ، كذلك في بعض اللغات الأحرف تكتب ملتصقة ببعض بدون مسافات مثل الصينية و من ناحية أخرى بعض اللغات تعتبر غنية بالتراكيب اللغوية مثل العربية حيث أن كلمة معينة يمكن أن يكون لها عدة تراكيب مختلفة مثل علم ، عمله ، تعلمه ، يتعلمون ، يتعلم ، الخ.
تعتبر اللغة العربية من أقدم اللغات ، ويقدر عمرها بحوالي 1500 سنة (مصدر) . مرت كتابة اللغة العربية بالكثير من التغييرات بسبب عمرها. " (1) البسملة كتبت بخط كوفي غير منقط ولا مشكّل. (2) نظام أبي الأسود الدؤلي المبكر ويَعتمد على تمثيل الحركات بنقاط حمراء تكتب فوق الحرف (الفتحة) أو تحته (الكسرة) أو بين يديه (الضمّة)، وتُستعمل النقطتان للتنوين. (3) تطور النظام بتنقيط الحروف. (4) نظام الخليل بن أحمد الفراهيدي المستعمل إلى اليوم، وهو وضع رموز مختلفة للحركات فيما تبقى النقاط لتمييز الحروف" (المصدر)
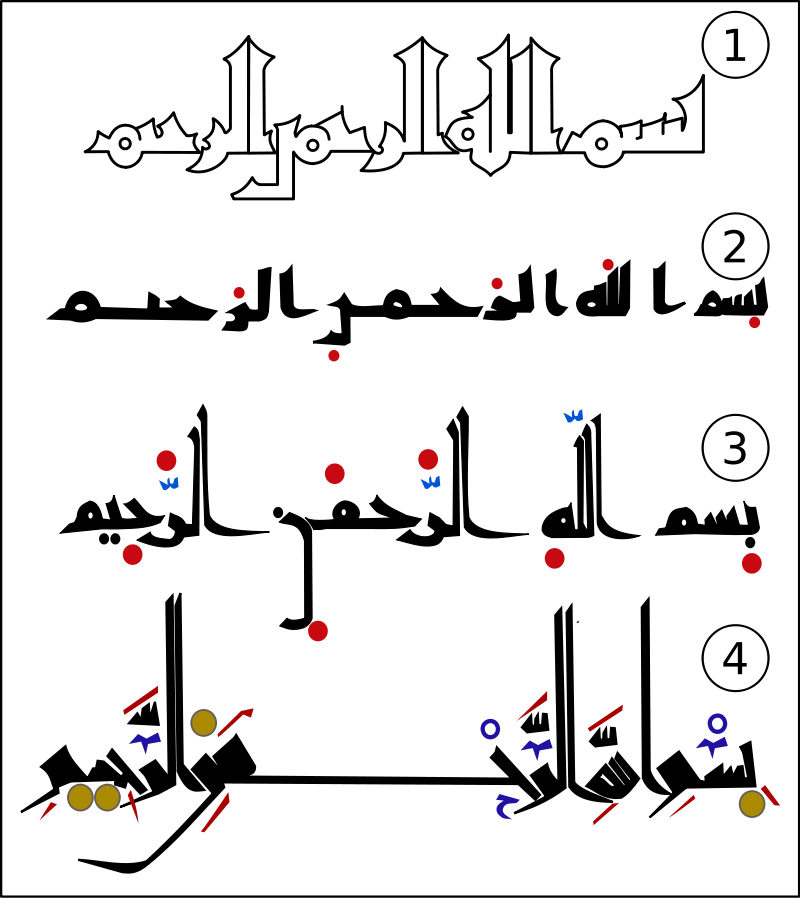
تطور الكتابة في اللغة العربية
كتابة اللغة العربية كما ذكرنا سالفاً تتأثر بالتراكيب المختلفة للكلمة. ولذلك ظهرت العديد من المعاجم مثل معجم مختار الصحاح لفهرسة المعاني للتراكيب باستخدام جذرالكلمة. بالإضافة إلى ذلك أضافت اللهجات في العصر الحديث الكثير من التعقيد للغة العربية من ناحية النطق والكتابة. قابلية اللغة العربية لإتصال الكثير من الأحرف أدت إلى مرونة كبيرة من ناحية الكتابة والقراءة. مثلاً: لا أعرفه ، ما أعرفه ، ما عرفتوش ، ماعرفته ، معرفتوش ، الخ. هناك إلتباس كبير في اللغة العربية على طريقة تحويل النطق إلى كتابة و ذلك لغياب long vowels في الكتابة الأصلية. لحل هذه المشكلة تم استخدام التشكيل لإزالة إي نوع من الإلتباس من ناحية النطق. مثلاً بدون أي سياق كلامي لا يمكن معرفة معنى كلمة "علم". بالإضافة إلى ذلك من ناحية الكتابة هناك اختلاف واسع من نايحة إذا كان حرف الواو متصل بالكلمة أو لا "وتكلم" أو "و تكلم" من ناحية كتابية الكثير منا يكتبها متصلة بالكلمة.
معالجة اللغات الطبيعية
مع ثورة تعلم الآلة بدءاً من عام 2012 ظهرت الكثير من الخوارزميات التي هدفها تمكين تطبيق هذه الثورة في علم معالجة اللغات الطبيعية. الهدف الرئيسي هو إنشاء نظام يمكنه فهم السياق language understanding ، إنشاء نصوص متنوعة Text Generation ، معرفة أجزاء الكلام Part of Speech Tagging ، الخ. مؤخراً ظهرت نماذج عملاقة مثل BERT, GPT, T5 and T-NLG معظم هذه النماذج تقوم على أساس تعليم نموذج كبير على بيانات مجمعة من شبكة الإنترنت. معظم هذه البيانات غير مصنفة وبالتالي من السهل معالجتها. بعد ذلك تتم عملية تقسيم الكلام tokenization وذلك لإيجاد وحدة صغيرة يمكن للنموذج التعامل معها. بسبب وجود عدد كبير من الكلام و حجم النموذج يتأثر بعدد tokens يتم غالباً تحديد عدد محدد ، غالباً أقل من 100 ألف. بما أنه عدد الكلمات في النصوص يكون غالباً أكثر يتم تقسيم هذه الوحدات إلى وحدات اصغر بإستخدام خوارزمية word piece tokenization أو تقسيم أجزاء الكلمات. بعد تحديد أجزاء الكلمات التي يمكن من خلالها فهم اللغة تتم عملية التدريب و التي غالباً تأخذ أيام إلى أسابيع ، وذلك بسبب أنه هذه النماذج تحديداً تحتاج إلى عدد كبير من البيانات غالباً أكثر من 40 جيجا من النصوص. بعد إنتهاء عملية التدريب يمكن إستخدام النماذج المدرب لمهام أخرى مثل تصنيف النصوص Text classification ، التعرف على أجزاء الكلام PoS tagging ، أنظمة تحدث chatbots ، الخ. هذه العملية تسمى fine-tuning وهي تعتبر أقل تعقيداً وتحتاج إلى عدد أقل من البيانات و الوقت. من ناحية التطبيقات العملية هناك الكثير مثل التعرف على المشاعر sentiment detection ، تكملة الكلام autocompletion ، الترجمة translation ، الخ.
تحديات وحلول
ذكرنا مسبقاً الاختلاف بين اللغة العربية وبقية اللغات من ناحية طريقة الكتابة ، النطق ، التراكيب اللغوية ، التشكيل ، النقاط ، الخ. كل هذه التحديات تعبر عن أهمية إنتشار البحوث في هذا المجال. عندما نبحث في الشبكة نرى أن اللغة الإنجليزية حظيت نصيب الأسد من ناحية الأبحاث المتعلقة بمعالجة اللغات الطبيعية. بالرغم من أن كثير من الأبحاث تحاول إسقاط الخوارزميات وتعميمها لبقية اللغات لكن لا يوجد إنتشار واسع للأبحاث في لغات أخرى مثل العربية. مقارنة باللغة العربية تعتبر الإنجليزية سهلة من ناحية القواعد ، تراكيب الكلمات ، تقسيم الكلام ، الخ. بالإضافة إلى توفر البيانات و النماذج المختلفة التي تم إثبات فعاليتها على اللغة الإنجليزية.

(المصدر) مقارنة الأبحاث في مؤتمر ACL
قمت ببحث بسيط عن عدد النتائج عند البحث عن Arabic vs English NLP وتوصلت إلى هذه النتائج في يوليو 2020
اللغة العربية من ناحية البحث و البيانات تعاني من نقص كبير. لتدريب لغة على مهمة معينة بإستخدام تعليم الآلة فإننا نحتاج الكثير من البيانات المصنفة annotated data وهذا يحتاج إلى الكثير من العمل خصوصاً في المهام الصعبة مثل إجابة الأسئلة Question Answering. بالإضافة إلى ذلك من المهم إنشاء بيانات نظيفة cleaned data باستخلاص النصوص المتنوعة من أرجاء الشبكة العنكبوتية. قد لا يكفي هذا لأننا نحتاج إلى خوارزميات تقسيم الكلام مناسبة tokenization وذلك بسبب التراكيب المختلفة للغة العربية. بالإضافة إلى إنشاء نماذج متخصصة لمواجهة المشاكل المتعلقة تحديداً باللغة العربية مثل تنوع التراكيب ، تنوع اللهجات ، نقص البيانات و التشكيل.
في عصر وسائل التواصل هناك الكثير من البيانات المتناثرة في الأرجاء، وتنتظر تجميعها وتنظيفها. هناك العديد من المواقع التي تحتوي على بيانات قيمة يمكننا من خلالها حل مشاكل نعجز عن حلها بالطرق التقليدية. بالإضافة إلى أن هناك الكثير من البحوث التي تهتم بنقل التعلم من نماذج مدربة على الكثير من البيانات مثل الإنجليزية إلى لغات أخرى مثل العربية cross-lingual transfer learning. بالإضافة إلى نماذج أخرى تهدف إلى إيجاد نماذج لإيجاد نقاط مشتركة بين مختلف اللغات ك multilingual BERT. من غير أن ننسى أن هناك العديد من البحوث التي بدأت تظهر لتكييف هذه النماذج للعربية مثل Arabert.
بالرغم من التحديات الكثيرة ، مازال هناك أمل كبير في توجه العديد من الباحثين لمواكبة معالجة اللغة العربية. مثلاً في مؤتمر ACL : Associations of Computational Linguistics و الذي يعتبر من أكبر المؤتمرات في مجال معالجات اللغة كان هناك 5 بحوث متعلقة باللغة العربية في عام 2020. من غير أن ننسى أهمية معالجة البيانات وتكييفها للنماذج المختلفة. بالإضافة إلى أهمية إنشاء مكاتب مفتوحة المصدر لتسريع عملية البحث في هذا المجال.
Other References








تعليقات
إرسال تعليق